技術(shù)實戰(zhàn) | 五度易鏈一站式大數(shù)據(jù)治理體系架構(gòu)詳解 數(shù)據(jù)處理服務(wù)篇
在大數(shù)據(jù)時代,企業(yè)數(shù)據(jù)資產(chǎn)的價值釋放,離不開高效、可靠的數(shù)據(jù)處理服務(wù)。作為五度易鏈一站式大數(shù)據(jù)治理體系的核心引擎,其數(shù)據(jù)處理服務(wù)模塊旨在為海量、多源、異構(gòu)的數(shù)據(jù)提供從采集、整合、加工到服務(wù)的全鏈路處理能力,構(gòu)建起支撐上層智能分析與業(yè)務(wù)應(yīng)用的數(shù)據(jù)基石。
一、核心定位與設(shè)計理念
五度易鏈數(shù)據(jù)處理服務(wù)并非孤立的技術(shù)堆砌,而是緊密融入其“采、存、管、算、用、治”一體化治理框架的關(guān)鍵一環(huán)。其設(shè)計秉承以下理念:
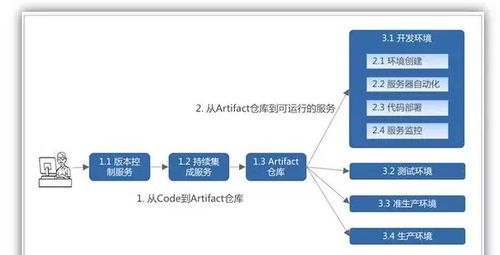
- 流水線化與自動化:將復(fù)雜的數(shù)據(jù)處理任務(wù)抽象為標(biāo)準(zhǔn)化的處理流水線(Pipeline),通過可視化編排與調(diào)度,實現(xiàn)從數(shù)據(jù)接入到產(chǎn)出的一鍵自動化執(zhí)行,極大提升數(shù)據(jù)開發(fā)與運維效率。
- 批流一體與實時化:統(tǒng)一支持批量數(shù)據(jù)處理與實時流數(shù)據(jù)處理。既能應(yīng)對T+1的傳統(tǒng)報表與分析需求,也能通過Flink等流計算引擎滿足實時監(jiān)控、風(fēng)險預(yù)警、個性化推薦等對時效性要求極高的場景。
- 質(zhì)量內(nèi)嵌與可觀測:在數(shù)據(jù)處理的關(guān)鍵環(huán)節(jié)(如清洗、轉(zhuǎn)換)內(nèi)置數(shù)據(jù)質(zhì)量校驗規(guī)則,實現(xiàn)“處理即治理”。提供全流程的任務(wù)監(jiān)控、血緣追溯、性能度量與日志審計,確保處理過程透明、可控、可信。
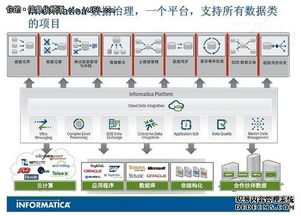
- 資源彈性與服務(wù)化:基于云原生架構(gòu),計算與存儲資源可按需彈性伸縮。數(shù)據(jù)處理能力以API或服務(wù)的形式對外提供,業(yè)務(wù)團隊可像使用水電一樣便捷地消費數(shù)據(jù)加工服務(wù),降低技術(shù)門檻。
二、架構(gòu)組成與核心功能
數(shù)據(jù)處理服務(wù)模塊通常由以下幾個核心子系統(tǒng)和組件構(gòu)成:
- 統(tǒng)一數(shù)據(jù)接入層:
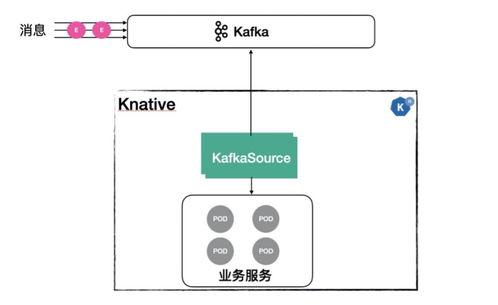
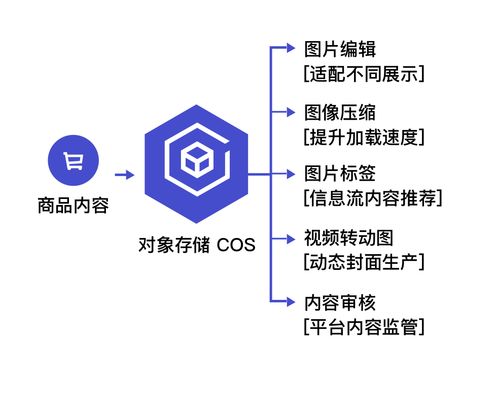
- 多源適配:支持從關(guān)系型數(shù)據(jù)庫(MySQL, Oracle)、NoSQL數(shù)據(jù)庫(MongoDB, Redis)、消息隊列(Kafka, RocketMQ)、日志文件、API接口、物聯(lián)網(wǎng)設(shè)備等各類數(shù)據(jù)源進行數(shù)據(jù)抽取或?qū)崟r采集。
- 增量同步:基于CDC(變更數(shù)據(jù)捕獲)、時間戳、增量表等多種技術(shù),實現(xiàn)高效、低延遲的增量數(shù)據(jù)同步,減少全量拉取帶來的資源與時間開銷。
- 數(shù)據(jù)處理引擎層:
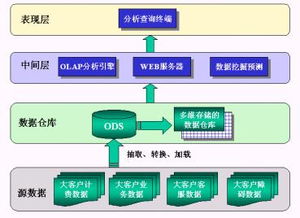
- 批處理引擎:集成Spark、MapReduce等,負(fù)責(zé)海量歷史數(shù)據(jù)的ETL(抽取、轉(zhuǎn)換、加載)、復(fù)雜聚合、模型訓(xùn)練等重計算任務(wù)。
- 流處理引擎:集成Flink、Spark Streaming等,負(fù)責(zé)對無界數(shù)據(jù)流進行實時過濾、聚合、關(guān)聯(lián)、風(fēng)控規(guī)則計算等,實現(xiàn)毫秒到秒級的延遲。
- SQL引擎:提供標(biāo)準(zhǔn)SQL接口,讓數(shù)據(jù)分析師和開發(fā)者能夠以熟悉的SQL語言操作大規(guī)模數(shù)據(jù)集,進行即席查詢與批處理,降低學(xué)習(xí)成本。
- 數(shù)據(jù)開發(fā)與調(diào)度中心:
- 可視化開發(fā):提供拖拽式的任務(wù)流程設(shè)計器,支持配置數(shù)據(jù)源、轉(zhuǎn)換規(guī)則(清洗、去重、標(biāo)準(zhǔn)化、關(guān)聯(lián))、輸出目標(biāo)等,快速構(gòu)建數(shù)據(jù)處理任務(wù)。
- 工作流調(diào)度:具備強大的DAG(有向無環(huán)圖)調(diào)度能力,能處理復(fù)雜的任務(wù)依賴關(guān)系,支持時間觸發(fā)、事件觸發(fā)、手動觸發(fā)等多種調(diào)度策略,保障任務(wù)按時、有序執(zhí)行。
- 腳本與UDF支持:允許開發(fā)人員編寫Python、Java、Scala等自定義腳本或UDF(用戶自定義函數(shù)),以滿足更復(fù)雜的業(yè)務(wù)邏輯處理需求。
- 數(shù)據(jù)質(zhì)量管理與監(jiān)控模塊:
- 過程監(jiān)控:實時監(jiān)控數(shù)據(jù)處理任務(wù)的運行狀態(tài)、資源消耗、數(shù)據(jù)吞吐量、處理延遲等關(guān)鍵指標(biāo),異常時及時告警。
- 質(zhì)量校驗:在任務(wù)節(jié)點中配置完整性、準(zhǔn)確性、一致性、時效性等質(zhì)量規(guī)則,對產(chǎn)出數(shù)據(jù)進行自動校驗,攔截問題數(shù)據(jù),生成質(zhì)量報告。
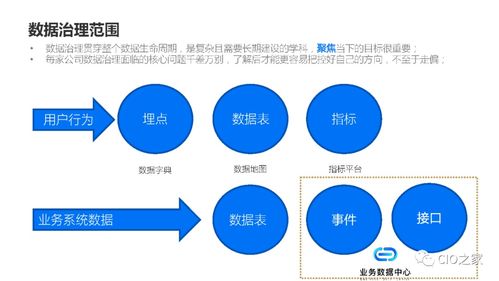
- 血緣與影響分析:自動捕獲并記錄數(shù)據(jù)在加工過程中的流轉(zhuǎn)路徑(血緣關(guān)系),可快速追溯數(shù)據(jù)來源、定位數(shù)據(jù)問題的影響范圍,為變更管理提供依據(jù)。
- 數(shù)據(jù)服務(wù)與輸出層:
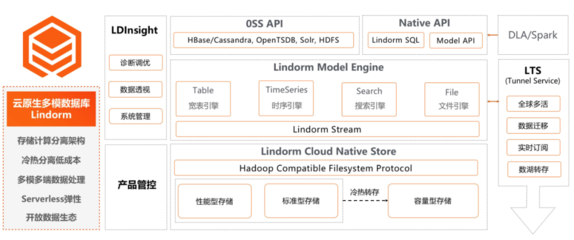
- 多樣化輸出:處理后的數(shù)據(jù)可寫入數(shù)據(jù)倉庫(如Hive)、數(shù)據(jù)湖、OLAP數(shù)據(jù)庫(如ClickHouse, Doris),或直接推送至消息隊列、API網(wǎng)關(guān),供下游報表系統(tǒng)、AI平臺、業(yè)務(wù)應(yīng)用直接調(diào)用。
- API服務(wù)化:將常用的數(shù)據(jù)查詢、指標(biāo)計算邏輯封裝成標(biāo)準(zhǔn)RESTful API,實現(xiàn)數(shù)據(jù)服務(wù)的敏捷交付與安全管控。
三、實戰(zhàn)價值與應(yīng)用場景
通過以上架構(gòu),五度易鏈的數(shù)據(jù)處理服務(wù)能為企業(yè)帶來顯著的實戰(zhàn)價值:
- 提升數(shù)據(jù)時效:實時流處理能力讓業(yè)務(wù)決策從“事后分析”走向“實時洞察”,如在金融反欺詐、電商實時大屏、運維監(jiān)控等場景快速響應(yīng)。
- 降低開發(fā)運維成本:自動化、可視化的開發(fā)運維平臺,將數(shù)據(jù)工程師從繁瑣的腳本編寫、任務(wù)監(jiān)控中解放出來,專注于業(yè)務(wù)邏輯本身。
- 保障數(shù)據(jù)可靠性:內(nèi)嵌的質(zhì)量管控與全鏈路可觀測性,確保了數(shù)據(jù)產(chǎn)出的準(zhǔn)確、一致與可信,為高層決策和合規(guī)審計提供堅實基礎(chǔ)。
- 賦能業(yè)務(wù)創(chuàng)新:敏捷的數(shù)據(jù)服務(wù)交付模式,使得業(yè)務(wù)部門能夠快速獲取所需數(shù)據(jù),驅(qū)動產(chǎn)品優(yōu)化、精準(zhǔn)營銷、智能風(fēng)控等創(chuàng)新應(yīng)用的落地。
###
數(shù)據(jù)處理服務(wù)是五度易鏈大數(shù)據(jù)治理體系中將“原始數(shù)據(jù)”轉(zhuǎn)化為“可用資產(chǎn)”的核心轉(zhuǎn)換器。其現(xiàn)代化、一體化的架構(gòu)設(shè)計,不僅解決了傳統(tǒng)數(shù)據(jù)開發(fā)中效率低下、質(zhì)量難控、實時性不足等痛點,更通過服務(wù)化的方式,讓數(shù)據(jù)能力得以沉淀、復(fù)用和規(guī)模化輸出,為企業(yè)構(gòu)建數(shù)據(jù)驅(qū)動型組織提供了強大的技術(shù)支撐。在具體落地時,企業(yè)需結(jié)合自身業(yè)務(wù)特點與技術(shù)棧,對該架構(gòu)進行適配與優(yōu)化,方能最大化其價值。
如若轉(zhuǎn)載,請注明出處:http://m.evuod.cn/product/71.html
更新時間:2026-06-18 12:15:39